Kubernetes Trends
Workloads tell the real story of how organizations deploy their applications and services on Kubernetes.
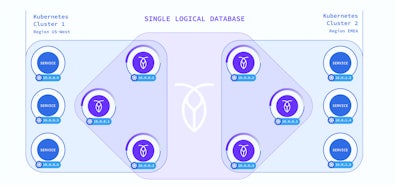
Get ReportIn my last blog post we looked at how we can deploy CockroachDB across multiple regions in Azure with the help of Cilium CNI. In this blog post we evolve this architecture to allow for the use of a mix of Kubernetes pods and virtual machines. Because CockroachDB is a single binary it makes it easy to deploy as a container or just run it natively on virtual machines. This type of architecture may be required for a number of reasons. As businesses consider their future cloud strategy and how they can move their existing applications workloads to the Public Cloud this type of hybrid architecture may be required. Perhaps the on-premises data centers do not have the capability to run a Kubernetes environment as this can be complex and requires additional infrastructure that may not be available. This is just one example but there are likely to be many. Now let’s take a closer look at the deployment details.
Azure Infrastructure Deployment
Some of the steps will look similar to my last blog post because some of the infrastructure elements are the same but I will still put them here for completeness. First, we’ll set a number of variables to make subsequent commands easier.
export vm_type="Standard_DS2_v2"
export rg="bookham-k3s-multi-region"
export clus1="crdb-k3s-eastus"
export clus2="crdb-k3s-westus"
export clus3="crdb-k3s-northeurope"
export loc1="eastus"
export loc2="westus"
export loc3="northeurope"
export dnsname="private.cockroach.internal"
Now that we have set our variable which you can adjust as you see fit. We are able to deploy the infrastructure with the Azure CLI to support the CockroachDB cluster. First we create a resource group to hold all of the resources we will create in Azure.
az group create --name $rg --location $loc1
The networking is spread across three regions. A VNet is created in each of the three regions and VNet Peers created to connect them all together. Each of the regions must have unique non-overlapping address space.
These three commands create a VNet in each of the three regions.
az network vnet create -g $rg -l $loc1 -n crdb-$loc1 --address-prefix 10.1.0.0/16 \
--subnet-name crdb-$loc1-sub1 --subnet-prefix 10.1.1.0/24
az network vnet create -g $rg -l $loc2 -n crdb-$loc2 --address-prefix 10.2.0.0/16 \
--subnet-name crdb-$loc2-sub1 --subnet-prefix 10.2.1.0/24
az network vnet create -g $rg -l $loc3 -n crdb-$loc3 --address-prefix 10.3.0.0/16 \
--subnet-name crdb-$loc3-sub1 --subnet-prefix 10.3.1.0/24
One of the critical elements of this demo is a Private Hosted DNS Zone in Azure. This allows us to control name resolution for our pods and virtual machines. If we don’t do this then Kubernetes and the virtual machines will use different solutions that have limited configuration options and are not able to integrate together. Kubernetes uses CoreDNS running as a pod inside Kubernetes. This is used for name resolution for all the pods and services running inside a given Kubernetes cluster. Virtual machines running inside Azure by default use the DNS service provided by Azure. This is really useful to get you up and running quickly but presents an issue in this solution. When you deploy virtual machines they are allocated a random DNS suffix.
ubuntu@mb-test-vm:~$ hostname -f
mb-test-vm.yn3ojvhzughuldx3eetkrprl4b.fx.internal.cloudapp.net
This random DNS suffix makes it tricky to configure CockroachDB in a consistent and automated manner particularly with regards to TLS certificates. In the example above the two elements before the internal.cloudapp.net are randomly generated. By using a DNS Private Zone we are able to control this and use a single consistent name we can factor into the CockroachDB start command. So create our DNS Private Zone using the following commands.
az network private-dns zone create -g $rg \
-n $dnsname
az network private-dns link vnet create -g $rg -n $loc1-DNSLink \
-z $dnsname -v crdb-$loc1 -e true
az network private-dns link vnet create -g $rg -n $loc2-DNSLink \
-z $dnsname -v crdb-$loc2 -e true
az network private-dns link vnet create -g $rg -n $loc3-DNSLink \
-z $dnsname -v crdb-$loc3 -e true
This will create the DNS Private Zone and link it to our three VNets.
There are a few further networking elements that need to be deployed to support our infrastructure, namely the Public IPs and network adaptors for the virtual machines, the Network Security Groups and rules to allow access to resources.
The commands below create the Network Security Groups and rules.
az network nsg create --resource-group $rg --location $loc1 --name crdb-$loc1-nsg
az network nsg create --resource-group $rg --location $loc2 --name crdb-$loc2-nsg
az network nsg create --resource-group $rg --location $loc3 --name crdb-$loc3-nsg
az network nsg rule create -g $rg --nsg-name crdb-$loc1-nsg -n NsgRuleSSH --priority 100 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 22 --access Allow \
--protocol Tcp --description "Allow SSH Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc2-nsg -n NsgRuleSSH --priority 100 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 22 --access Allow \
--protocol Tcp --description "Allow SSH Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc3-nsg -n NsgRuleSSH --priority 100 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 22 --access Allow \
--protocol Tcp --description "Allow SSH Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc1-nsg -n NsgRulek8sAPI --priority 200 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 6443 --access Allow \
--protocol Tcp --description "Allow Kubernetes API Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc2-nsg -n NsgRulek8sAPI --priority 200 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 6443 --access Allow \
--protocol Tcp --description "Allow Kubernetes API Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc3-nsg -n NsgRulek8sAPI --priority 200 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 6443 --access Allow \
--protocol Tcp --description "Allow Kubernetes API Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc1-nsg -n NsgRuleNodePorts --priority 300 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 30000-32767 --access Allow \
--protocol Tcp --description "Allow Kubernetes NodePort Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc2-nsg -n NsgRuleNodePorts --priority 300 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 30000-32767 --access Allow \
--protocol Tcp --description "Allow Kubernetes NodePort Access to all VMS."
az network nsg rule create -g $rg --nsg-name crdb-$loc3-nsg -n NsgRuleNodePorts --priority 300 \
--source-address-prefixes '*' --source-port-ranges '*' \
--destination-address-prefixes '*' --destination-port-ranges 30000-32767 --access Allow \
--protocol Tcp --description "Allow Kubernetes NodePort Access to all VMS."
Next the Public IPs and Network Adaptors.
az network public-ip create --resource-group $rg --location $loc1 --name crdb-$loc1-ip1 --sku standard
az network public-ip create --resource-group $rg --location $loc1 --name crdb-$loc1-ip2 --sku standard
az network public-ip create --resource-group $rg --location $loc1 --name crdb-$loc1-ip3 --sku standard
az network public-ip create --resource-group $rg --location $loc2 --name crdb-$loc2-ip1 --sku standard
az network public-ip create --resource-group $rg --location $loc2 --name crdb-$loc2-ip2 --sku standard
az network public-ip create --resource-group $rg --location $loc2 --name crdb-$loc2-ip3 --sku standard
az network public-ip create --resource-group $rg --location $loc3 --name crdb-$loc3-ip1 --sku standard
az network public-ip create --resource-group $rg --location $loc3 --name crdb-$loc3-ip2 --sku standard
az network public-ip create --resource-group $rg --location $loc3 --name crdb-$loc3-ip3 --sku standard
az network nic create --resource-group $rg -l $loc1 --name crdb-$loc1-nic1 --vnet-name crdb-$loc1 --subnet crdb-$loc1-sub1 --network-security-group crdb-$loc1-nsg --public-ip-address crdb-$loc1-ip1
az network nic create --resource-group $rg -l $loc1 --name crdb-$loc1-nic2 --vnet-name crdb-$loc1 --subnet crdb-$loc1-sub1 --network-security-group crdb-$loc1-nsg --public-ip-address crdb-$loc1-ip2
az network nic create --resource-group $rg -l $loc1 --name crdb-$loc1-nic3 --vnet-name crdb-$loc1 --subnet crdb-$loc1-sub1 --network-security-group crdb-$loc1-nsg --public-ip-address crdb-$loc1-ip3
az network nic create --resource-group $rg -l $loc2 --name crdb-$loc2-nic1 --vnet-name crdb-$loc2 --subnet crdb-$loc2-sub1 --network-security-group crdb-$loc2-nsg --public-ip-address crdb-$loc2-ip1
az network nic create --resource-group $rg -l $loc2 --name crdb-$loc2-nic2 --vnet-name crdb-$loc2 --subnet crdb-$loc2-sub1 --network-security-group crdb-$loc2-nsg --public-ip-address crdb-$loc2-ip2
az network nic create --resource-group $rg -l $loc2 --name crdb-$loc2-nic3 --vnet-name crdb-$loc2 --subnet crdb-$loc2-sub1 --network-security-group crdb-$loc2-nsg --public-ip-address crdb-$loc2-ip3
az network nic create --resource-group $rg -l $loc3 --name crdb-$loc3-nic1 --vnet-name crdb-$loc3 --subnet crdb-$loc3-sub1 --network-security-group crdb-$loc3-nsg --public-ip-address crdb-$loc3-ip1
az network nic create --resource-group $rg -l $loc3 --name crdb-$loc3-nic2 --vnet-name crdb-$loc3 --subnet crdb-$loc3-sub1 --network-security-group crdb-$loc3-nsg --public-ip-address crdb-$loc3-ip2
az network nic create --resource-group $rg -l $loc3 --name crdb-$loc3-nic3 --vnet-name crdb-$loc3 --subnet crdb-$loc3-sub1 --network-security-group crdb-$loc3-nsg --public-ip-address crdb-$loc3-ip3
The final step of the infrastructure setup is to use cloud init to perform some initial configuration of each of the virtual machines. This is required to ensure that each of the virtual machines take advantage of the DNS Private Zone. There are a couple of additional settings in there like installing curl and setting the log file output. Those are not critical for this setup.
cat << EOF > cloud-init.txt
#cloud-config
package_upgrade: true
packages:
- curl
output: {all: '| tee -a /var/log/cloud-init-output.log'}
runcmd:
- set -e
- grep -v -G domain-name /etc/dhcp/dhclient.conf > dhclient.tmp
- echo "supersede domain-name \"$dnsname\";" >> dhclient.tmp
- echo "prepend domain-name-servers 168.63.129.16;" >> dhclient.tmp
- sudo cp /etc/dhcp/dhclient.conf /etc/dhcp/dhclient.conf.old
- sudo cp dhclient.tmp /etc/dhcp/dhclient.conf
- sudo dhclient -v
EOF
This file will be used during the deployment of the virtual machines into each of the regions.
Three virtual machines in region one.
az vm create \
--resource-group $rg \
--location $loc1 \
--name crdb-$loc1-node1 \
--image UbuntuLTS \
--nics crdb-$loc1-nic1 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc1 \
--name crdb-$loc1-node2 \
--image UbuntuLTS \
--nics crdb-$loc1-nic2 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc1 \
--name crdb-$loc1-node3 \
--image UbuntuLTS \
--nics crdb-$loc1-nic3 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
Three virtual machines in region two.
az vm create \
--resource-group $rg \
--location $loc2 \
--name crdb-$loc2-node1 \
--image UbuntuLTS \
--nics crdb-$loc2-nic1 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc2 \
--name crdb-$loc2-node2 \
--image UbuntuLTS \
--nics crdb-$loc2-nic2 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc2 \
--name crdb-$loc2-node3 \
--image UbuntuLTS \
--nics crdb-$loc2-nic3 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
And finally three in the last region.
az vm create \
--resource-group $rg \
--location $loc3 \
--name crdb-$loc3-node1 \
--image UbuntuLTS \
--nics crdb-$loc3-nic1 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc3 \
--name crdb-$loc3-node2 \
--image UbuntuLTS \
--nics crdb-$loc3-nic2 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
az vm create \
--resource-group $rg \
--location $loc3 \
--name crdb-$loc3-node3 \
--image UbuntuLTS \
--nics crdb-$loc3-nic3 \
--admin-username ubuntu \
--generate-ssh-keys \
--custom-data cloud-init.txt
That’s all the infrastructure components completed.
K3s Kubernetes Deployment
The first step is to install a K3s leader node. To do this we will be using k3sup (said ‘ketchup’). k3sup is a light-weight utility to get from zero to KUBECONFIG with k3s on any local or remote VM. All you need is ssh access and the k3sup binary to get kubectl access immediately.
The first step is to install k3sup on the host workstation you will be using to configure the demo environment. This could be your workstation or a dedicated builder machine.
curl -sLS https://get.k3sup.dev | sh
sudo install k3sup /usr/local/bin/
k3sup --help
Next we need to deploy k3s on to our first virtual machine in region one. Use the k3sup command below to install the first node. Be sure to replace (Public IP) with the public IP of the node. Retrieve the Public IP address of the first node in region one
LEADERR1=$(az vm show -d -g $rg -n crdb-$loc1-node1 --query publicIps -o tsv)
Now use k3sup to create the first Kubernetes cluster.
k3sup install \
--ip=$LEADERR1 \
--user=ubuntu \
--sudo \
--cluster \
--k3s-channel stable \
--merge \
--local-path $HOME/.kube/config \
--context=$clus1
Next you can add the agent nodes to the k3s This will be where our workloads are run from. In this example we are going to add three agents. Obtain the Public IP address of the second node.
AGENT1R1=$(az vm show -d -g $rg -n crdb-$loc1-node2 --query publicIps -o tsv)
Now use k3sup to add the node to the existing cluster.
k3sup join \
--ip $AGENT1R1 \
--user ubuntu \
--sudo \
--k3s-channel stable \
--server \
--server-ip $LEADERR1 \
--server-user ubuntu \
--sudo
Repeat this for the third node.
Obtain the Public IP address of the third node.
AGENT2R1=$(az vm show -d -g $rg -n crdb-$loc1-node3 --query publicIps -o tsv)
Now use k3sup to add the node to the existing cluster.
k3sup join \
--ip $AGENT2R1 \
--user ubuntu \
--sudo \
--k3s-channel stable \
--server \
--server-ip $LEADERR1 \
--server-user ubuntu \
--sudo
Follow the same steps for the second region.
LEADERR2=$(az vm show -d -g $rg -n crdb-$loc2-node1 --query publicIps -o tsv)
Now use k3sup to create the second Kubernetes cluster.
k3sup install \
--ip=$LEADERR2 \
--user=ubuntu \
--sudo \
--cluster \
--k3s-channel=stable \
--merge \
--local-path $HOME/.kube/config \
--context=$clus2
Next you can add the agent nodes to the k3s This will be where our workloads are run from. In this example we are going to add two agents. Obtain the Public IP address of the second node.
AGENT1R2=$(az vm show -d -g $rg -n crdb-$loc2-node2 --query publicIps -o tsv)
Now use k3sup to add the node to the existing cluster.
k3sup join \
--ip $AGENT1R2 \
--user ubuntu \
--sudo \
--k3s-channel stable \
--server \
--server-ip $LEADERR2 \
--server-user ubuntu \
--sudo
Repeat this for the third node.
Obtain the Public IP address of the third node.
AGENT2R2=$(az vm show -d -g $rg -n crdb-$loc2-node3 --query publicIps -o tsv)
Now use k3sup to add the node to the existing cluster.
k3sup join \
--ip $AGENT2R2 \
--user ubuntu \
--sudo \
--k3s-channel stable \
--server \
--server-ip $LEADERR2 \
--server-user ubuntu \
--sudo
Now Kubernetes is deployed to two of the regions; we can deploy CockroachDB to these two clusters.
CockroachDB Kubernetes Deployment
Now that we have deployed the required infrastructure to two of our regions, both based on k3s distribution of Kubernetes, we are able to deploy CockroachDB. The reason to tackle these two regions first is that the deployment method for the virtual machines will be very different.
To deploy CockroachDB I have taken advantage of a Python script provided here which deploys CockroachDB to GKE. I have had to adapt and make a few changes to this script and template Kubernetes manifests to make it work for this use case. The first change is to add two additional lines to the StatefulSet template under the pod spec section.
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
This allows the pods within this StatefulSet to use the host network of the node where it is running. It is required so that the pods running inside Kubernetes are routable to the CockroachDB nodes running natively on virtual machines that are not inside Kubernetes. For Pods running with hostNetwork, you should explicitly set its DNS policy as above. Also in this demo I have adjusted the storage requirement down to 10GB from 100GB so consider changing this to meet your requirements.
Now we can take a closer look at the Python script. Change directory into the multiregion folder.
cd multiregion
Retrieve the kubectl “contexts” for your clusters:
kubectl config get-contexts
At the top of the setup.py script, fill in the contexts map with the zones of your clusters and their “context” names, this has been done in the files provided in this demo but is for the regions set out at the beginning. e.g.:
contexts = {
'eastus': 'crdb-k3s-eastus',
'westus': 'crdb-k3s-westus',
}
In the setup.py script, fill in the regions map with the zones and corresponding regions of your clusters, for example:
regions = {
'eastus': 'eastus',
'westus': 'westus',
}
Setting regions is optional, but recommended, because it improves CockroachDB’s ability to diversify data placement if you use more than one zone in the same region. If you aren’t specifying regions, just leave the map empty. Now run the script!
Run the setup.py script:
python setup.py
In this demo I have used eastus and westus for my Kubernetes regions and northeurope as my virtual machines region. If you are using the same then you will be able to use the two configmaps below. If you are using other regions and IP addressing then you can use them as examples but you will need to edit the contents to reflect the regions you are using. Here is a snippet below that shows where you need to modify.
westus.svc.cluster.local:53 { # <---- Modify
log
errors
ready
cache 10
forward . 10.2.1.4 10.2.1.5 10.2.1.6 { # <---- Modify
}
}
private.cockroach.internal:53 { # <---- Modify
log
errors
ready
cache 10
forward . 168.63.129.16:53 { # <---- Modify
}
}
Then apply the new ConfigMaps.
kubectl replace -f eastus.yaml --context crdb-k3s-eastus --force
kubectl replace -f westus.yaml --context crdb-k3s-westus --force
Confirm that the CockroachDB pods in each cluster say 1/1 in the READY column - This could take a couple of minutes to propagate, indicating that they’ve successfully joined the cluster.
kubectl get pods --selector app=cockroachdb --all-namespaces --context $clus1
kubectl get pods --selector app=cockroachdb --all-namespaces --context $clus2
At this point CockroachDB will be up and running across two regions. To access the admin console later in the demo a user needs to be created in CockroachDB with admin rights. To do this a secure client can be deployed to one of the Kubernetes clusters.
kubectl create -f client-secure.yaml --namespace $loc1
Now that the pod has been created we can exec into the container so we can run our commands.
kubectl exec -it cockroachdb-client-secure -n $loc1 -- ./cockroach sql --certs-dir=/cockroach-certs --host=cockroachdb-public
Create a user and make admin.
CREATE USER <username> WITH PASSWORD 'cockroach';
GRANT admin TO <username>;
\q;
Finally we need to add the third and final region.
Virtual Machine Deployment
The following steps need to be completed on each of the nodes which you wish to add to the cluster.
- SSH to the node and the required folder structure.
LOC3NODE1=$(az vm show -d -g $rg -n crdb-$loc3-node1 --query publicIps -o tsv)
ssh ubuntu@$LOC3NODE1
- Now create the required folder structure.
mkdir cockroach
cd cockroach
mkdir certs
mkdir my-safe-directory
exit
- Now we need to transfer some files over to each node. This would be the required certificates to join the nodes to the cluster. We will also transfer a shell script that will start Cockroach on each node. Make sure you are currently in the root of the repo for the next set of commands.
scp startdb.sh ubuntu@$LOC3NODE1:/home/ubuntu/cockroach
cd multiregion/certs
scp ca.crt client.root.crt client.root.key ubuntu@$LOC3NODE1:/home/ubuntu/cockroach/certs
cd ../my-safe-directory
scp ca.key ubuntu@$LOC3NODE1:/home/ubuntu/cockroach/my-safe-directory
- Now all the files have been copied across to the node we can SSH in and install and run Cockroachdb. First we download the binary, extract and copy to our path.
ssh ubuntu@$LOC3NODE1
curl https://binaries.cockroachdb.com/cockroach-v21.2.3.linux-amd64.tgz | tar -xz && sudo cp -i cockroach-v21.2.3.linux-amd64/cockroach /usr/local/bin/
cockroach --version
cd cockroach
chmod 766 startdb.sh
cd certs
chmod 700 *
cd ..
./startdb.sh
- Repeat these steps on the other two nodes…
LOC3NODE2=$(az vm show -d -g $rg -n crdb-$loc3-node2 --query publicIps -o tsv)
ssh ubuntu@$LOC3NODE2
- Create the required folder structure.
mkdir cockroach
cd cockroach
mkdir certs
mkdir my-safe-directory
exit
- Transfer the files over as we did on the first node. Again, make sure you are in the root directory of the repo.
scp startdb.sh ubuntu@$LOC3NODE2:/home/ubuntu/cockroach
cd multiregion/certs
scp ca.crt client.root.crt client.root.key ubuntu@$LOC3NODE2:/home/ubuntu/cockroach/certs
cd ../my-safe-directory
scp ca.key ubuntu@$LOC3NODE2:/home/ubuntu/cockroach/my-safe-directory
- Now all the files have been copied across to the node we can SSH in and install and run Cockroachdb. First we download the binary, extract and copy to our path.
ssh ubuntu@$LOC3NODE2
curl https://binaries.cockroachdb.com/cockroach-v21.2.3.linux-amd64.tgz | tar -xz && sudo cp -i cockroach-v21.2.3.linux-amd64/cockroach /usr/local/bin/
cockroach --version
cd cockroach
chmod 766 startdb.sh
cd certs
chmod 700 *
cd ../my-safe-directory
chmod 700 *
cd ..
./startdb.sh
- Now deploy CockroachDB to Node 3….
LOC3NODE3=$(az vm show -d -g $rg -n crdb-$loc3-node3 --query publicIps -o tsv)
ssh ubuntu@$LOC3NODE3
- Create the required file structure for the final time.
mkdir cockroach
cd cockroach
mkdir certs
mkdir my-safe-directory
exit
- Transfer the files over as we did on the other nodes. Make sure you are in the root directory of the repo.
scp startdb.sh ubuntu@$LOC3NODE3:/home/ubuntu/cockroach
cd multiregion/certs
scp ca.crt client.root.crt client.root.key ubuntu@$LOC3NODE3:/home/ubuntu/cockroach/certs
cd ../my-safe-directory
scp ca.key ubuntu@$LOC3NODE3:/home/ubuntu/cockroach/my-safe-directory
- Now all the files have been copied across to the node we can SSH in and install and run Cockroachdb. First we download the binary, extract and copy to our path.
ssh ubuntu@$LOC3NODE3
curl https://binaries.cockroachdb.com/cockroach-v21.2.3.linux-amd64.tgz | tar -xz && sudo cp -i cockroach-v21.2.3.linux-amd64/cockroach /usr/local/bin/
cockroach --version
cd cockroach
chmod 766 startdb.sh
cd certs
chmod 700 *
cd ../my-safe-directory
chmod 700 *
cd ..
./startdb.sh
- We should now have all nine nodes available across three regions. We can easily access the Cockroach admin UI by using kubectl to forward the traffic.
kubectl port-forward cockroachdb-0 8080 --context $clus1 --namespace $loc1
- You will then be able to access the Admin UI via your browser. http://localhost:8080
In the UI you should see all of the nine nodes, six coming from Kubernetes and three from Virtual Machines.
CockroachDB Deployment Pattern Thoughts
In some use cases it may be necessary to mix different deployment patterns for your CockroachDB cluster. It’s possible to mix Kubernetes Pods and virtual machines as you have seen in this demo. This is achieved by exposing the Kubernetes pods via the host network. Typically I would not recommend this approach as it reduces the mobility of your application pods as they are tied to a single node. However in the case of CockroachDB it is typical to do this due to the resource requirements of each pod.
The main challenge I found with this deployment pattern was that virtual machines and Kubernetes rely on their own deployment of DNS. For this solution to function we need to ensure that both instances of DNS work in harmony. This has been done by hosting a Private DNS Zone in Azure and forwarding requests from CoreDNS to Azure. This ensures that all the pods are able to successfully resolve the names of all the nodes that make up the cluster, whether they are pods in Kubernetes or virtual machines.
This demo shows the true flexibility of CockroachDB and how it can be deployed across many different platforms, its architecture of a single binary makes it incredibly easy to deploy and ideal to run inside a container. Give it a go! Here is the link to the github repo.